
ABBYY FineReader Engine – twórz aplikacje wyodrębniające tekst!
Zestaw deweloperski ABBYY FineReader Engine 12 umożliwia twórcom oprogramowania tworzenie aplikacji, które wyodrębniają informacje tekstowe ze zdigitalizowanych dokumentów papierowych lub obrazów.
Produkt
Abbyy FineReader Engine jest dostępny dla systemów: Windows, Linux, Mac OS i wbudowanych platform. Szczegółową specyfikację możliwości poszczególnych systemów znajdziecie Państwo w poniższym dokumencie:
Samouczek — filmy wideo ułatwiające rozpoczęcie pracy
Obejrzyj te krótkie filmy, aby dowiedzieć się, jak zintegrować program ABBYY FineReader Engine z Twoją aplikacją.
Zobacz, w jaki sposób różne profile przetwarzania pozwalają łatwo uzyskać najlepsze wyniki rozpoznawania.
- Inicjalizacja silnika FineReader i dokumentów procesowych: kliknij TUTAJ
- Użycie komponentów interfejsu użytkownika w celu zbudowania własnego GUI i sprawdzenia parametry rozpoznawania: kliknij TUTAJ
Funkcjonalność
Kompleksowy zestaw technologii rozpoznawania
W celu rozpoznawania tekstu program ABBYY FineReader Engine oferuje kompleksowy zestaw technologii rozpoznawania. Dostarczane technologie obejmują rozpoznawanie tekstów drukowanych (OCR), pisma ręcznego blokowego (ICR) oraz znaków optycznych (OMR) i rozpoznawanie kodów kreskowych (OBR). Jako lider na rynku, firma ABBYY oferuje największą liczbę języków OCR, które można łączyć indywidualnie.
Wydajne narzędzia do przetwarzania plików PDF
Software development kit (SDK) umożliwia konwersję skanów, zdjęć cyfrowych, plików TIFF, JPEG, BMP i innych formatów obrazu, do wielu rodzajów przeszukiwanych formatów PDF i PDF/A. Ponadto umożliwia import plików PDF i PDF /A oraz ich przetwarzanie na różne sposoby. Do obu typów konwertowania plików PDF program ABBYY FineReader Engine oferuje szeroki zakres opcji i narzędzi, a także umożliwia edytowanie i tworzenie dokumentów elektronicznych zgodnie ze standardami PDF/A-3 oraz standardami ZUGFeRD dla e-faktur.
Wykorzystanie sztucznej inteligencji i nauki maszynowej zapewnia precyzyjne odwzorowanie dokumentów i większą dokładność
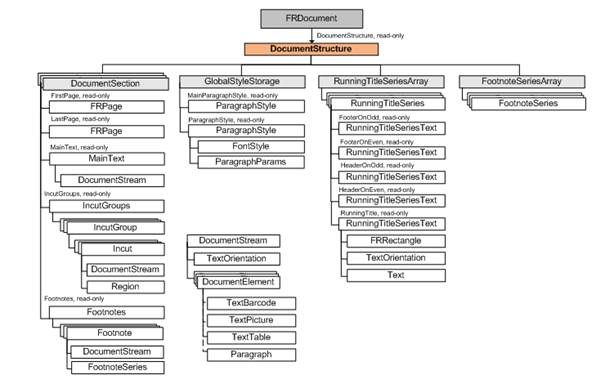
Za pomocą algorytmów opartych na sztucznej inteligencji, nauce maszynowej oraz technologii adaptacyjnego rozpoznawania dokumentów firmy ABBYY, program ABBYY FineReader Engine analizuje układ dokumentu. Na tym etapie jest on dzielony na poszczególne strony – układ każdej z nich jest systematycznie sprawdzany pod kątem rozmieszczenia tekstu, obrazów, kodów kreskowych i elementów tabeli. Jednocześnie badany jest dokument jako całość i wykrywana jest jego logiczna struktura. W jaki sposób system FineReader Engine wykrywa strukturę logiczną dokumentu?
Wykorzystanie wielordzeniowych procesorów
Elastyczna i skalowalna architektura programu ABBYY FineReader Engine umożliwia wykorzystanie wielordzeniowych procesorów i przetwarzanie obrazów równolegle na wielu wątkach. W ten sposób można znacznie zwiększyć prędkość przetwarzania. Domyślnie program ABBYY FineReader Engine automatycznie wykrywa, czy korzystać z przetwarzania wieloprocesorowego. Zależy to od kilku czynników, takich jak liczba dostępnych fizycznych lub logicznych rdzeni procesora w systemie obliczeniowym, liczba rdzeni procesora zdefiniowanych w licencji oraz liczba stron zawartych w dokumencie. W razie potrzeby programista może z łatwością zmienić ustawienia wieloprocesorowe i dostosować liczbę procesów, które powinny zostać uruchomione.
Obsługa chmury i środowisk wirtualnych
Program ABBYY FineReader Engine obsługuje nowy rodzaj licencji — licencję gotową do pracy w chmurze. Umożliwia on przedsiębiorstwom poszerzenie spektrum aplikacji i usług oferowanych przez nowoczesne platformy chmury obliczeniowej, takie jak Amazon AWS i Microsoft Azure. Obsługiwane są również środowiska wirtualne, np.: VMware Workstation,ESXi, Docker Containers i Oracle VM VirtualBox.
Wstępne przetwarzanie obrazu: zaawansowane funkcje wstępnego przetwarzania obrazu
Po pobraniu obrazów program ABBYY FineReader Engine wykonuje szereg funkcji przetwarzania obrazu w celu poprawy jakości obrazów dokumentów w procesie rozpoznawania. Technologia ta wykorzystuje zestaw funkcji wstępnego przetwarzania i zwiększa jakość obrazów. W ten sposób nawet obrazy o niskiej jakości lub dokumenty sfotografowane za pomocą smartfonów mogą być efektywnie przetwarzane i prawidłowo rozpoznawane.
Profile rozpoznawania dla szybkiego wdrożenia
Program ABBYY FineReader Engine posiada zestaw predefiniowanych profili przetwarzania, które zostały zaprojektowane dla scenariuszy częstego użytkowania. Dzięki ich wykorzystaniuprogramiści oszczędzają pracę i mogą wdrażać funkcje przetwarzania OCR bez zaawansowanej znajomości jego parametrów.
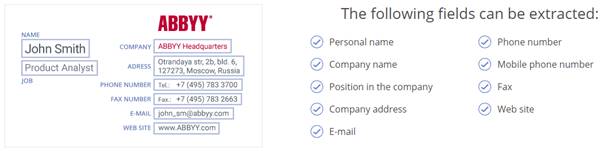
Gotowa do użycia technologia rozpoznawania wizytówek
Wizytówki to określone dokumenty, często fotografowane lub skanowane jako kilka obrazów na jednej stronie. Gotowa do użycia technologia rozpoznawania wizytówek jest zintegrowana z silnikiem FineReader i może być używana bezpośrednio podczas działania. API zapewnia pełen zestaw funkcji do przetwarzania wizytówek: od specjalnych funkcji przetwarzania wstępnego po zapewniających dostęp do wyodrębnionych danych.
Klasyfikacja dokumentów z wykorzystaniem nauczania maszynowego i NLP
Program ABBYY FineReader Engine udostępnia interfejs API do klasyfikacji dokumentów, który umożliwia tworzenie aplikacji automatycznie klasyfikujących dokumenty i sortujących je do predefiniowanych klas. Zaawansowana klasyfikacja wykorzystuje nowoczesne technologie, takie jak nauka maszynowa i przetwarzanie języka naturalnego. Są one w stanie wykryć nawet subtelne różnice pomiędzy poszczególnymi kategoriami dokumentów i umożliwiają stworzenie elastycznych i skalowalnych procesów klasyfikacji.
Komponenty interfejsu użytkownika
Silnik ABBYY FineReader Engine oferuje pięć komponentów wizualnych opartych na ActiveX, które umożliwiają tworzenie graficznego interfejsu użytkownika do przeglądania i wstępnego przetwarzania obrazów oraz edycji i weryfikacji rozpoznanego tekstu, a także monitorowania procesu. Elementy wizualne zostały zaprojektowane zgodnie z wieloletnim doświadczeniem firmy ABBYY w tworzeniu aplikacji dla użytkowników końcowych.
Szczegółowa dokumentacja i wsparcie SDK
Szczegółowa dokumentacja z wieloma wyjaśnieniami i próbkami kodów ułatwia integrację funkcji rozpoznawania tekstu i przechwytywania danych z aplikacji.
Parametry techniczne
Zestaw programistyczny do tworzenia oprogramowania ABBYY FineReader Engine oferuje zaawansowane funkcje dla programistów tworzących aplikacje dla platform z systemami Windows, Linux i Mac OS.
ABBYY FineReader Engine 12 dla Windows — wymagania techniczne:
- komputer PC z procesorem kompatybilnym z procesorem x86 (1 GHz lub większym);
- system operacyjny: Windows Server 2016, Windows Server 2012, Windows Server 2012 R2 z aktualizacją z kwietnia 2014 (KB2919355), Windows Server 2008 R2 SP1, Windows 10, Windows 8.1 z aktualizacją w kwietniu 2014 r. (KB2919355), Windows 8, Windows 7 SP1;
- przetestowane rozwiązania chmurowe i środowiska wirtualne: Azure Cloud Services, Azure Service Fabric, Azure Virtual Machines, Amazon EC2, Microsoft Hyper-V Server 2008, Microsoft Hyper-V Server 2008 R2 SP1, Microsoft Hyper-V Server 2012, Microsoft Hyper-V Server 2012 R2, Microsoft Hyper-V Server 2016, Oracle VM VirtualBox 5.2, Parallels Desktop for Mac 13.0.1, VMware ESXi 6.5, VMware Workstation Player 12.5, VMware Workstation Pro 14.0.0, Silnik ABBYY FineReader Engine może być również uruchomiony w kontenerze Docker na platformach podpartych;
- skaner, aparat cyfrowy lub modem faksowy kompatybilny z TWAIN-em do skanowania lub importu obrazów;
- do treningu wzorców, edycji słowników i skanowania za pomocą interfejsu użytkownika:
- karta graficzna i monitor (minimalna rozdzielczość 1024×768),
- program Microsoft® Internet Explorer 8.0 lub nowszy,
- w celu poprawnego wykrywania czcionek należy zainstalować czcionki zawarte w dokumentach;
- narzędzia deweloperskie: Interfejs programowania aplikacji (API) programu ABBYY FineReader Engine for Windows jest zgodny ze standardem COM i może być łatwo używany w aplikacjach C/C++, Visual Basic, .NET, Delphi, Java lub innych narzędziach programistycznych obsługujących komponenty COM; silnik może być przystosowany do stosowania w językach skryptowych, takich jak VBS, JS i Perl.
ABBYY FineReader Engine 12 dla Linux
Program ABBYY FineReader Engine 12 dla systemu Linux został zaprojektowany dla glibc w wersji 2.11 i nowszej. Jeśli potrzebujesz programu ABBYY FineReader Engine dla starszych wersji glibc, skontaktuj się z biurem ABBYY. W przypadku biblioteki dynamicznej FineReader Engine należy korzystać ze standardowych bibliotek libstdc++.so.6, libgcc_s.so.1 i libgomp.so.1.
Wymagania techniczne:
- komputer z procesorem kompatybilnym z procesorem x86 (1 GHz lub większym) obsługującym zestawy instrukcji SSE i SSE2;
- system operacyjny: Fedora 27, 26, 25, Red Hat Enterprise Linux 7.4, 6.9, Debian GNU/Linux 9.2, 8.8, Ubuntu 17.10, 16.04.1 LTS, 14.04.5 LTS, CentOS 7.3, 6.9;
- ALT Linux 8 (brak obsługi kluczy Wibu);
- przetestowane rozwiązania chmurowe i środowiska wirtualne: wirtualne maszyny Microsoft Azure, Amazonka EC2, Serwer Hyper-V Microsoft 2012 R2, Serwer Hyper-V Microsoft 2016, Oracle VM VirtualBox 5.2, VMware ESXi 6.5, VMware Workstation Player 12.5, VMware Workstation Pro 14.0.0.0, Linux KVM;
- narzędzia deweloperskie: silnik FineReader firmy ABBYY dla systemu Linux udostępnia natywne API C/C++ oraz Java wrapper, dlatego aplikacje muszą być pisane w języku C/C++ lub Java.
ABBYY FineReader Engine 12 dla Apple MacBooka — wymagania techcznie:
- komputer PC z procesorem Intel (x86) 1 GHz lub większym;
- system operacyjny: Mac OS X (10.12.x, 10.13.x);
- w celu poprawnego wykrywania czcionek należy zainstalować czcionki zawarte w dokumentach;
- narzędzia deweloperskie: wersja OS X udostępnia tylko natywne API C/C++, dlatego aplikacje muszą być zapisane w C/C++.
Więcej informacji na temat parametrów rozwiązania ABBYY FineReader 12 można znaleźć na stronie producenta: https://www.abbyy.com/ocr-sdk/technical-specifications/
Ceny
ABBYY FineReader Engine jest narzędziem programistycznym umożliwiającym wyposażenie dowolnej aplikacji w funkcje rozpoznawania pisma drukowanego. Aby przygotować autorskie rozwiązanie wyposażone w funkcje OCR należy zakupić pakiet programistyczny. Do udostępniania użytkownikom końcowym aplikacji z modułem OCR konieczne jest wykupienie licencji uruchomieniowej RTL na każde stanowisko, na którym będzie działał moduł OCR.
Licencje RTL konfigurowane są indywidualnie pod potrzeby klienta. Na ich funkcjonalność i cenę wpływa wiele czynników m.in. produktywność (ilość stron możliwych do przetworzenia w skali miesiąca), obsługiwane formaty danych, czas trwania wspracia technicznego oraz update assurance itd.
Zapraszamy do kontaktu w celu uzyskania indywidualnej wyceny.
Materiały dodatkowe
Zobacz pozostałe produkty

ABBYY Timeline
ABBYY Timeline to kompleksowa platforma do analizy procesów, za pomocą której można szybko i intuicyjnie przeprowadzić transformację całego przedsiębiorstwa. Oprogramowanie umożliwia firmom wykorzystywanie informacji zgromadzonych w ich systemach do tworzenia wizualnych modeli procesów, analizowania ich w czasie rzeczywistym i identyfikowania na tej podstawie ograniczeń. Pozwala też na przewidywanie wyników, efektów oraz podejmowanie na ich podstawie decyzji dotyczących inwestycji technologicznych.
ABBYY FineReader Engine – twórz aplikacje wyodrębniające tekst!
Zestaw deweloperski ABBYY FineReader Engine 12 umożliwia twórcom oprogramowania tworzenie aplikacji, które wyodrębniają informacje tekstowe ze zdigitalizowanych dokumentów papierowych lub obrazów.

ABBYY FlexiCapture SDK technologia przechwytywania danych
Silnik ABBYY FlexiCapture SDK reprezentuje najnowszą generację technologii przechwytywania danych. Pozwala na szybkie tworzenie rozwiązań do wydobywania danych z formularzy i dokumentów dowolnego rodzaju lub złożoności.
Zaufali nam

























